Our framework of online CLIP adaptation at test-time 💡
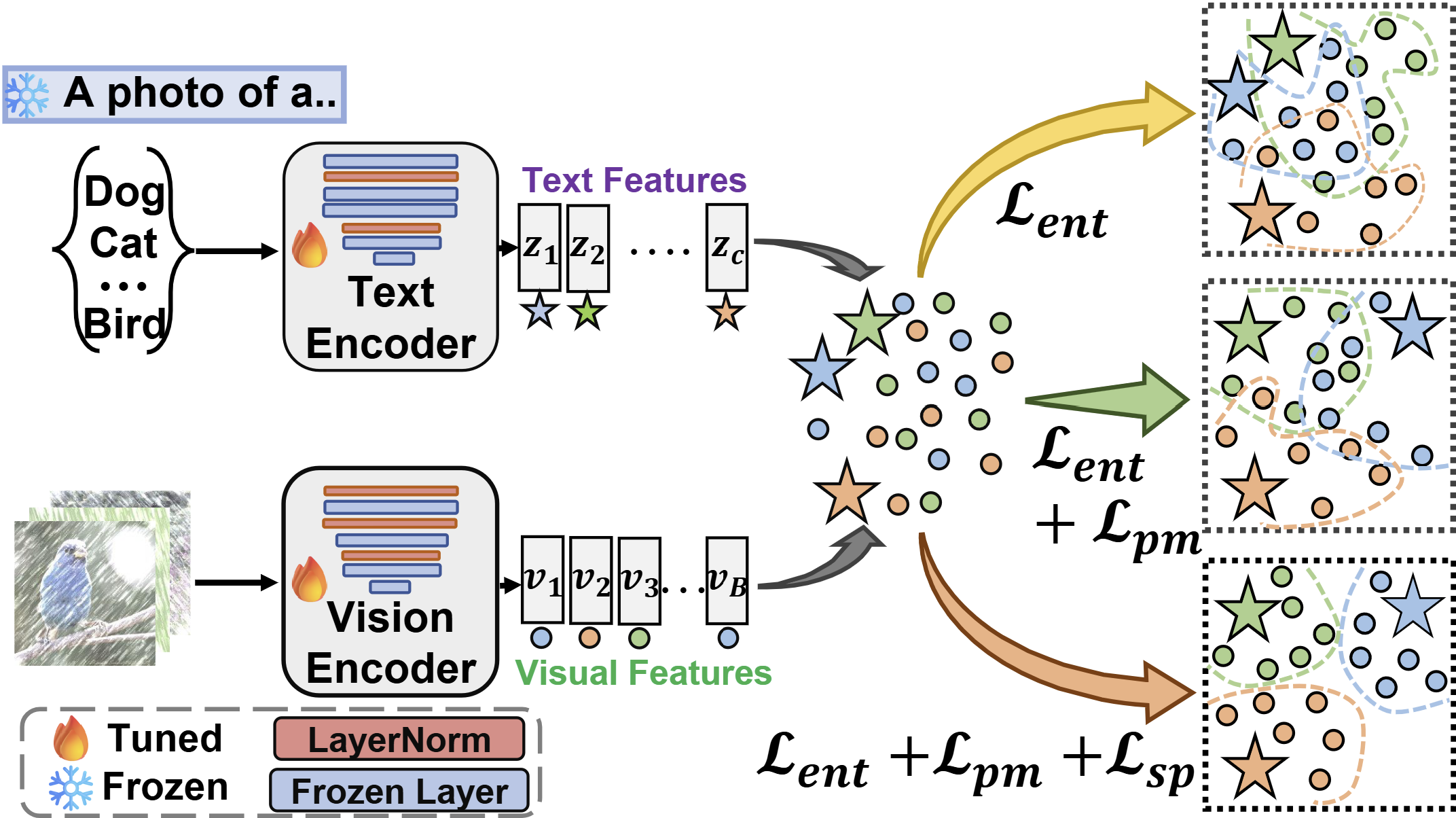
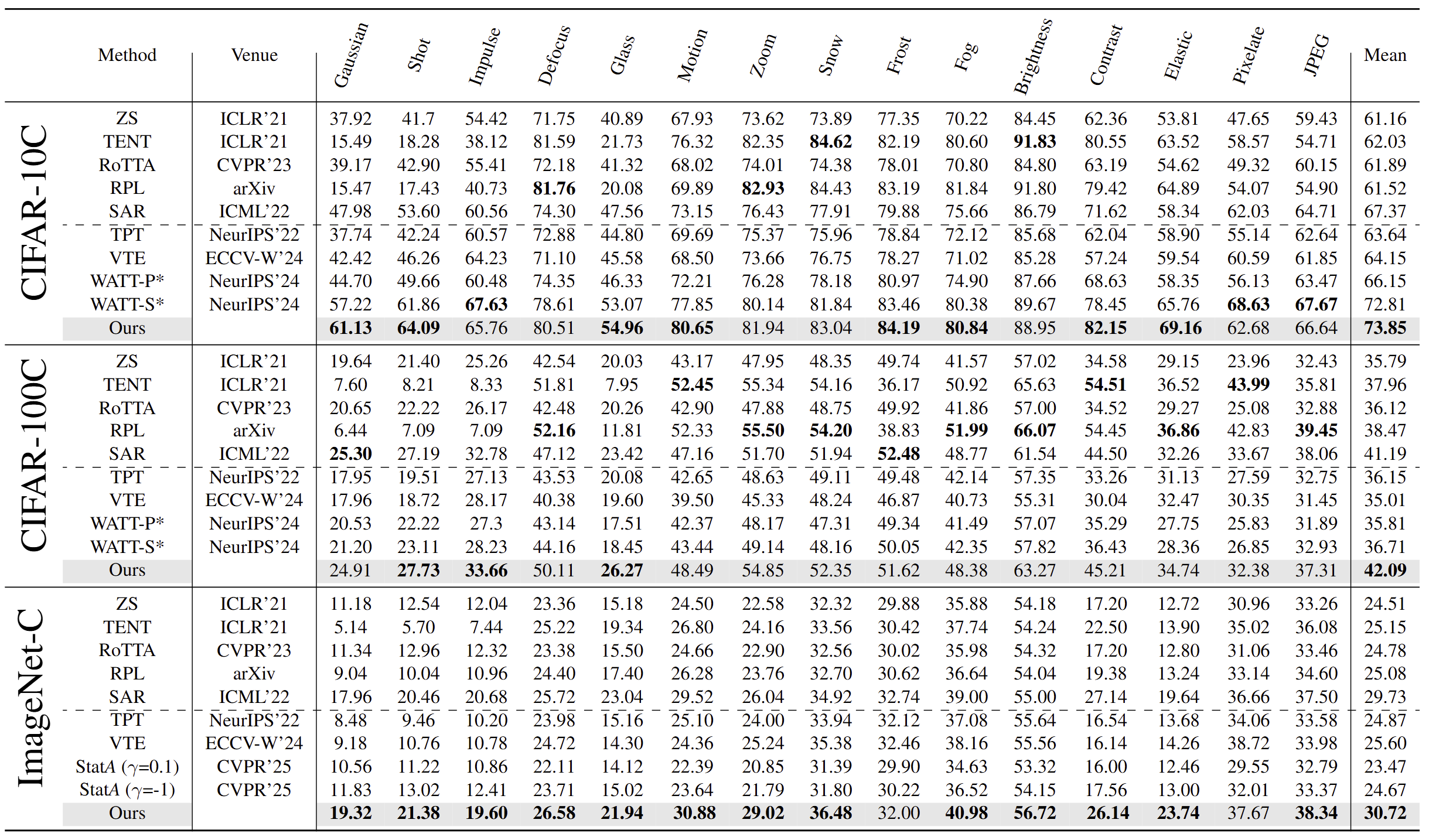
Although open-vocabulary classification models like Contrastive Language Image Pretraining (CLIP) have demonstrated strong zero-shot learning capabilities, their robustness to common image corruptions remains poorly understood. Through extensive experiments, we show that zero-shot CLIP lacks robustness to common image corruptions during test-time, necessitating the adaptation of CLIP to unlabeled corrupted images using test-time adaptation (TTA). However, we found that existing TTA methods have severe limitations in adapting CLIP due to their unimodal nature. To address these limitations, we propose BATCLIP, a bimodal online TTA method designed to improve CLIP's robustness to common image corruptions. The key insight of our approach is not only to adapt the visual encoders for improving image features but also to strengthen the alignment between image and text features by promoting a stronger association between the image class prototype, computed using pseudo-labels, and the corresponding text feature. We evaluate our approach on benchmark image corruption datasets and achieve state-of-the-art results in online TTA for CLIP. Furthermore, we evaluate our proposed TTA approach on various domain generalization datasets to demonstrate its generalization capabilities.
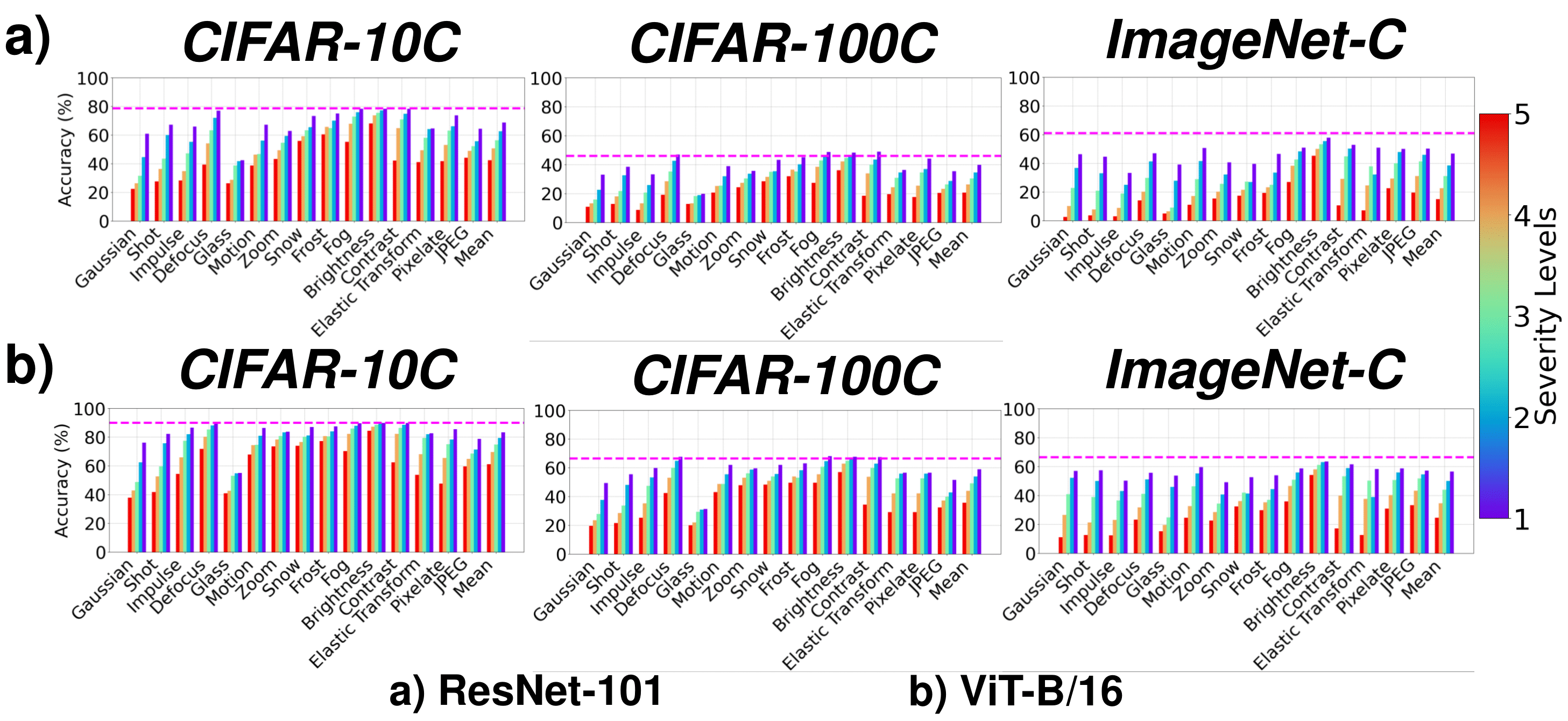
Dashed lines show zero-shot CLIP performance on corresponding source test sets (clean).

@inproceedings{maharana2025batclip,
title={BATCLIP: Bimodal Online Test-Time Adaptation for CLIP},
author={Maharana, Sarthak Kumar and Zhang, Baoming and Karlinsky, Leonid and Feris, Rogerio and Guo, Yunhui},
booktitle={International Conference on Computer Vision (ICCV)},
year={2025}
}