AVReCAP Framework
A memory-efficient buffer stores fusion-layer parameter snapshots; at each time step, KL-divergence over modality statistics guides selective retrieval before a single online adaptation step.
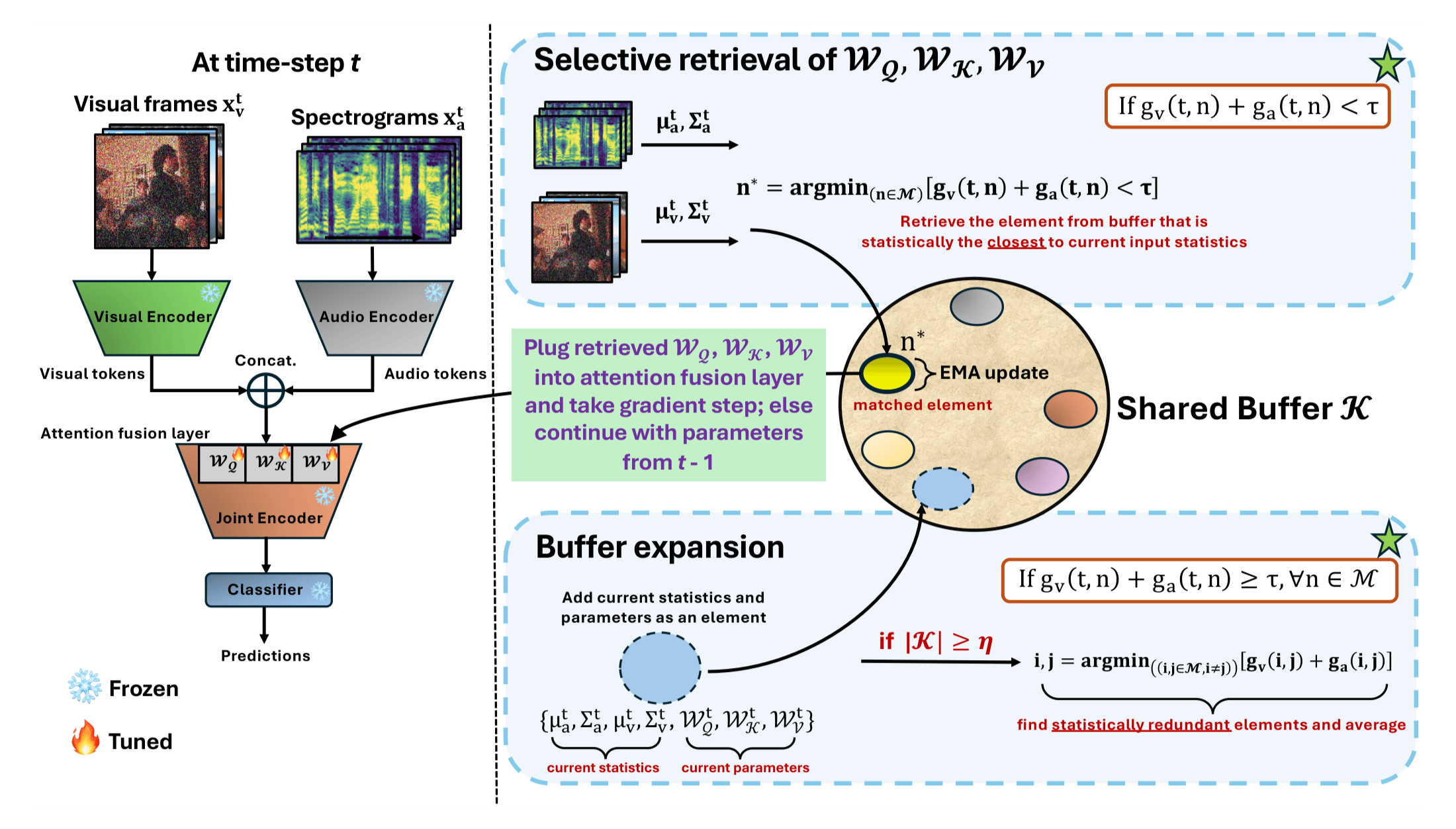
AVReCAP at time-step t: audio-visual inputs are summarized by modality-specific Gaussian statistics. A KL-divergence criterion compares the current batch against elements in shared buffer K. If a close match is found (within threshold τ), stored attention fusion parameters (WQ, WK, WV) are retrieved, adapted with READ-style losses, and written back. Otherwise, a new buffer element is added and redundant entries are merged to respect memory budget η. Only the fusion layer is adapted — audio and visual encoders remain frozen.