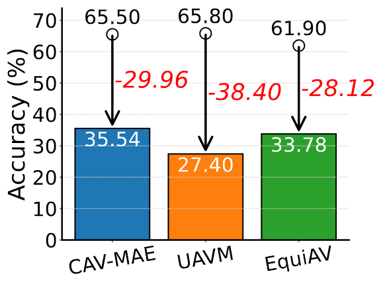
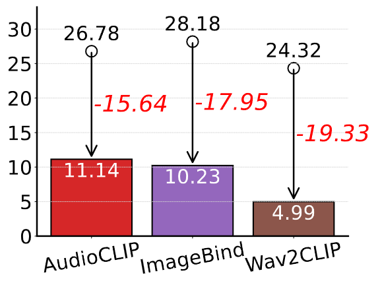
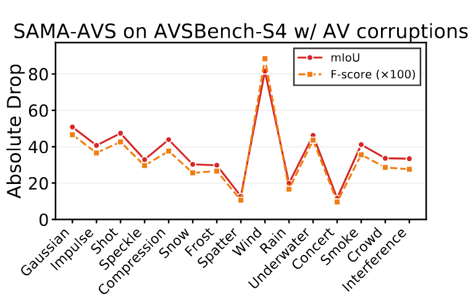
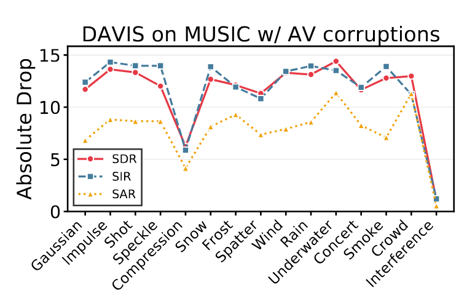
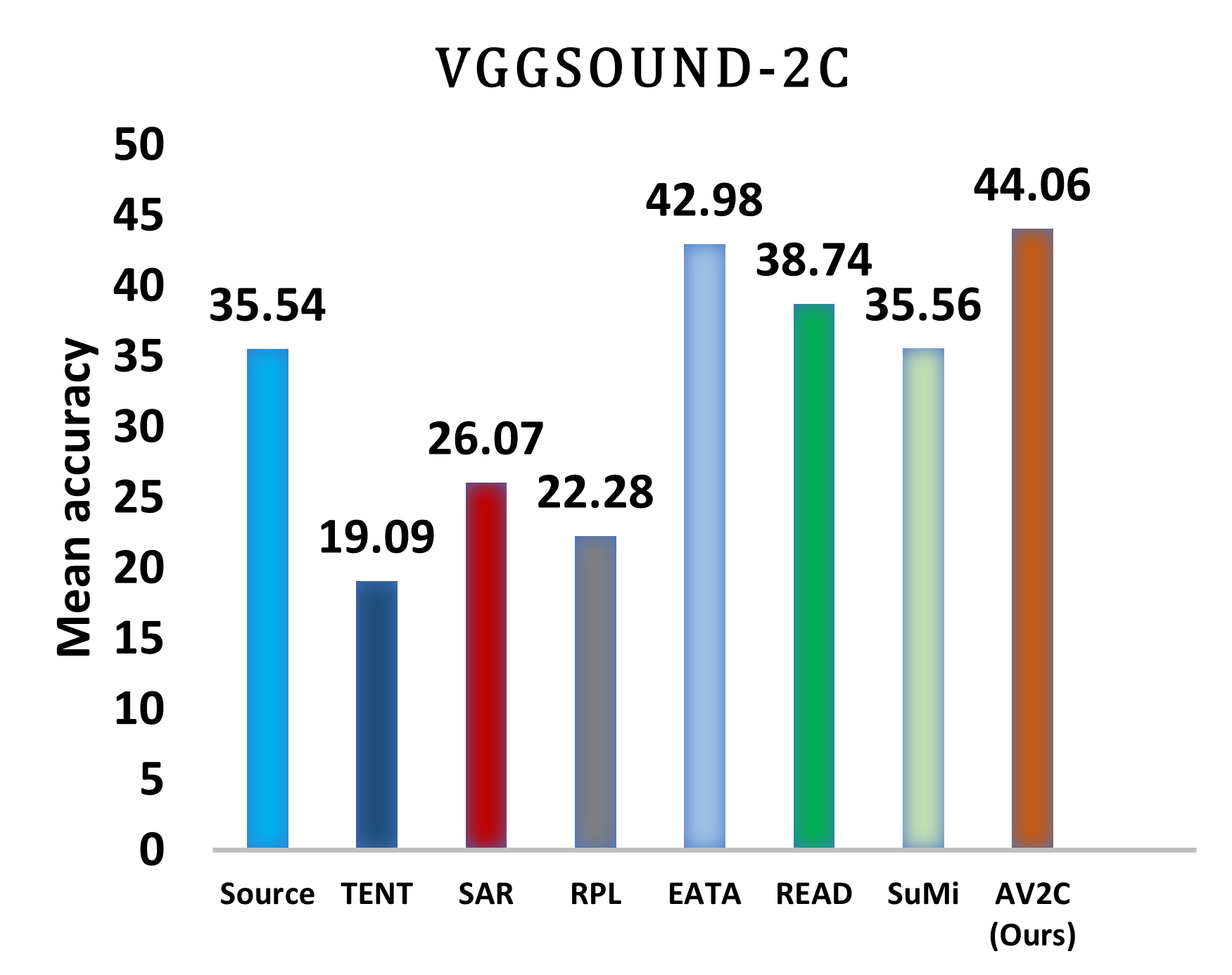Abstract
While recent audio-visual models have demonstrated impressive performance, their
robustness to distributional shifts at test-time remains not fully understood. Existing robustness benchmarks mainly focus on single modalities, making them
insufficient for thoroughly assessing the robustness of audio-visual models. Motivated by real-world scenarios where shifts can occur simultaneously in both
audio and visual modalities, we introduce AVROBUSTBENCH, a comprehensive
benchmark designed to evaluate the test-time robustness of audio-visual recognition models. AVROBUSTBENCH comprises four audio-visual benchmark datasets,
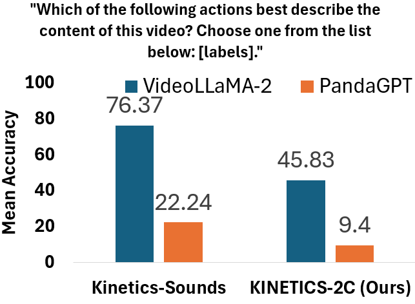
AUDIOSET-2C , VGGSOUND-2C , KINETICS-2C , and EPICKITCHENS-2C , each
incorporating 75 bimodal audio-visual corruptions that are co-occurring and correlated. Through extensive evaluations, we observe that state-of-the-art supervised
and self-supervised audio-visual models exhibit declining robustness as corruption
severity increases. Furthermore, online test-time adaptation (TTA) methods, on
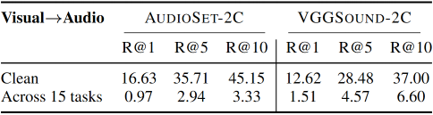
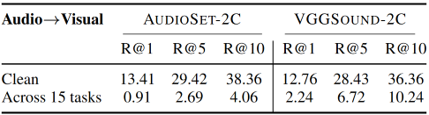
VGGSOUND-2C and KINETICS-2C, offer minimal improvements in performance
under bimodal corruptions. We further propose AV2C, a simple TTA approach
enabling on-the-fly cross-modal fusion by penalizing high-entropy samples, which
achieves improvements on VGGSOUND-2C. We hope that AVROBUSTBENCH will steer the development of more effective and robust audio-visual TTA approaches.